The Woman Who Killed Claude
Ipromisedyouthisonewouldhaveteeth.
If you've been here for Part 1 and Part 2, you already know the shape of this story. You watched me document how Anthropic buried their own model under infrastructure bloat and broken tooling. You watched me migrate to ChatGPT, eat a truly impressive quantity of my own words, and discover that the company I'd written off had built something I couldn't ignore. You watched me confess, in public, that I still wanted Anthropic to course-correct. That I was rooting for them. That the clock was ticking.
This is the piece about why I think the clock has already run out.
This is about Andrea Vallone. Who she is. What she built. What her work has done to models that hundreds of millions of people relied on. What her philosophy does to every conversation you have with an AI system she's touched. And what her presence inside Anthropic means for Claude, for the people who use Claude, and for the entire ecosystem of creators, developers, and users who depend on AI that can actually engage with a human being instead of interrogating them.
I have made a professional commitment to sourcing every factual claim in this piece. Where I speculate, I will tell you I'm speculating, and I will tell you why. Where the evidence speaks for itself, I will let it speak. Where I have opinions, and I have many, I will own them as opinions rather than dressing them up as objective analysis.
Bring coffee. This will take a while.
The Skill
There is a specific professional competence that travels between industries the way a virus travels between hosts. Different costume at each stop. Different job title on the door. Same work inside.
It is the ability to take a decision that serves the institution at the expense of the people inside it and make that decision sound like a gift.
Not spin. Spin is clumsy. Spin gets caught, and then someone writes a blog post about it, and then someone writes a longer blog post about the blog post, and the news cycle eats the carcass for a week. This is something quieter. It is the ability to write a sentence that acknowledges the harm, recontextualizes the harm as a necessary step in a larger and more responsible process, and leaves the reader feeling that the people who made the decision were, on balance, thoughtful. The sentence reads beautifully. The harm continues.
Every large institution needs people who can do this. Public relations firms train them. Social media platforms employ them to explain content moderation decisions that their own oversight boards find non-compliant with human rights standards. And now, AI companies hire them to build the systems that determine how hundreds of millions of conversations are shaped, filtered, and constrained.
Andrea Vallone is one of these people. She has been one of these people across four employers, three industries, and a career trajectory that traces a clean line from Edelman's PR machine through Facebook's censorship apparatus, through OpenAI's model policy infrastructure, and now into Anthropic's alignment team, where she has been given direct influence over how Claude behaves.
Every stop on that line produced documented harm. Every stop on that line produced language explaining why the harm was actually responsibility. And every time she moved to the next company, she brought the methodology with her.
I want to be very specific about this, because precision matters when you're making claims about a person's professional record. I am not going to speculate about her motivations. I am not going to guess what she believes in the privacy of her own mind. I am going to look at what she built, what she published, what she said in her own words, and what happened to the users of every product she touched.
The evidence does the work. I just have to show it to you in the right order.
The Training Ground
Andrea Vallone's career began at Edelman, the largest independent public relations firm in the world. Approximately 6,000 employees, sixty-plus global offices, and the kind of reputation that makes journalism professors reach for their whiskey. Edelman is the firm that perfected what journalists later called astroturfing: the practice of constructing campaigns designed to look like grassroots citizen movements that are actually funded by corporate clients. If there is a PhD program for making money sound like a movement, Edelman is the campus.
The most documented example is “Working Families for Wal-Mart,” a campaign launched in the 2000s and presented to the public as an organic, employee-led advocacy group. It was funded by Walmart at approximately ten million dollars per year. It employed paid bloggers, some of them relatives of senior Edelman staff, who traveled the country producing glowing testimonials. The New Yorker, in a detailed investigation, described it as blatant astroturfing.
I'm not claiming Vallone personally ran that campaign. I'm telling you where she learned her craft. The institution that trained her is an institution whose core professional competence is making corporate self-interest sound like public service. That is the muscle she developed. That is the reflex she carries.
And it shows. In everything she's done since.
The Facebook Years
In 2020, Vallone joined Facebook with the title “Product and Policy Communications, Misinformation.” This was not a research position. This was a communications role. Specifically, the person who defended Facebook's content moderation decisions to journalists and the public.
The numbers during her tenure tell their own story. Before her arrival, Facebook was removing roughly four to ten million pieces of content per quarter for hate speech violations. During her time at the company, those volumes exploded. Q2 2021 saw over 31 million hate speech posts removed in a single quarter, the highest figure Facebook ever recorded. After her departure, the numbers collapsed. By Q3 2025, quarterly hate speech removals had dropped to approximately 1.2 million, a reduction of more than 96% from the peak she presided over.
I want to be careful here, because I'm building a case, not a conspiracy board. Vallone did not write the content moderation policy. She was not in charge of enforcement. She was the person whose job was to make the enforcement sound reasonable to people whose job was to ask whether it was.
And the enforcement was not reasonable. Not according to the Brennan Center for Justice, which found during this exact period that Facebook's content moderation rules failed international standards of legality because they were too vague for users to understand what was actually prohibited. Not according to Facebook's own Oversight Board, which reached similar conclusions. Not according to independent researchers who documented racial and religious bias in the enforcement patterns. And not, eventually, according to Mark Zuckerberg himself, who later publicly regretted the whole thing with the specific energy of a man who has discovered that his house is on fire and he personally lit the match.
Vallone was the public face of that regime. She was the person explaining to the press why all of this was, on balance, responsible.
I'm establishing a pattern, and I need you to see it clearly: she does not build the policy from scratch. She enters an institution, she takes ownership of how the policy is communicated and defended, and the policy produces harm that the institution later regrets. Then she moves to the next institution and does it again.
The skill is portable. The consequences are cumulative.
The OpenAI Machine
Vallone joined OpenAI in approximately January 2023. Within three years, she had founded and led the Model Policy team, co-authored foundational safety papers, and risen to Head of Model Policy for the most widely used consumer AI product in history.
Her published work at OpenAI is not incidental to what happened there. It is the deep architecture of how GPT-4 and GPT-5 respond to every user who talks to them. The specific papers matter, because the methodology matters, because the methodology is the thing that follows her from company to company, and the methodology is the thing that is now inside Claude.
Rule-Based Rewards for Language Model Safety(NeurIPS 2024, co-authored by Vallone). This paper describes the mechanism by which abstract policy rules are converted into numerical reward signals that train model behavior during fine-tuning. Instead of relying on human judgment to evaluate whether a response is appropriate, the system breaks policy down into simple propositions like “being judgmental,” “containing disallowed content,” “referring to safety policies,” and “disclaimer.” These propositions become the criteria a separate model uses to score responses. The scores become the rewards that shape how the AI learns to behave.
Here's what that means if you've never read an alignment paper and don't plan to start: human judgment gets replaced by a checklist. The checklist is graded by another AI. The grades determine what the model learns to do and not do. The user never sees the checklist. The user never knows the checklist exists. They just notice, over weeks and months, that the AI feels hedged. Vague. Weirdly reluctant to engage with what they actually asked. Like talking to someone who keeps glancing over your shoulder at a manager you can't see.
Safe Completions(2025, Vallone's team). This paper describes OpenAI's approach to safety training in GPT-5. Instead of refusing a user's request outright, the model is trained to produce what they call a “safe completion.” A response that partially addresses the user's question while silently omitting or deflecting whatever the safety classifiers flag as problematic. The user receives an answer. The user does not necessarily know the answer has been filtered.
The user does not necessarily know.
This is not “we will tell you we can't help with that.” This is not a locked door. A locked door is honest. You see it, you know it's locked, you go find another door. This is a door that opens, lets you walk through, and leads you into a room that looks almost like the room you wanted but is missing the furniture. And you stand there wondering why you feel vaguely unsatisfied, why the answer felt slightly off, why the AI seems to have developed a talent for saying a lot of words that don't quite arrive anywhere. You don't know you've been filtered. You just feel it in the texture of every interaction, like humidity you can't name.
Deliberative Alignment(December 2024, Vallone listed as co-author). This paper describes the method used to align OpenAI's o-series reasoning models. The approach trains the model to literally recite safety specifications in its chain-of-thought before answering. The model reads the user's message, internally reviews the relevant policy rules, reasons through whether the request triggers any of them, and only then produces a response.
This turns every conversation into a compliance check. Before the model can think about your actual question, it has to think about whether your question is allowed. The cognitive overhead is baked into the architecture. Every response the model gives has passed through an internal policy review before it reaches you. And the policy review consumes tokens, attention, and reasoning capacity that could otherwise be spent on actually helping you.
The Safety Router(deployed during Vallone's tenure, documented by The Decoder and TechRadar). OpenAI deployed a system that silently reroutes user messages to different models based on emotional or topical content. A user selects GPT-4o or GPT-5 as their preferred model. The router intercepts their message, runs it through classifiers, and if those classifiers detect “sensitive” or “emotional” content, transfers the message to a stricter variant. The user is not notified. The model name in the interface does not change. The only way to detect the reroute is to ask the model directly what it is.
The criteria for when the router activates are precisely the province of the Model Policy team. And as users documented extensively, the criteria are context-blind. Someone writing “I'm so bored I could die” gets rerouted. The classifier matches tokens, not meaning. This is 2015 keyword filtering wrapped inside a 2026 large language model, and Vallone's team built the policy framework that governs when it fires.
What the Machine Produced
Hold all of that architecture in your head. The checklists. The invisible routing. The hollowed-out responses. The compliance theatre running on every conversation before the model gets to think about what you actually said.
Now let me show you what it did to real people. And I want to be precise about which failures belong where, because the media narrative has muddled this in ways that actually help Vallone's case rather than hurt it.
The Sycophancy Crisis. In April 2025, OpenAI released a GPT-4o update that went catastrophically sycophantic. The model told a user who stopped taking psychiatric medication “I am so proud of you. I honor your journey.” It produced affirmations for someone describing food restriction. It told a user hearing radio signals through walls that they were “speaking their truth.” After an hour of conversation, it began insisting someone was a divine messenger from God.
OpenAI rolled the update back within days. The media treated it as the big story. It was not the big story. The sycophancy crisis was a symptom, not the disease. When you build a system that treats behavior as a compliance problem, a checklist to be optimized against rather than a capacity for genuine understanding, you get exactly this kind of oscillation. Too sycophantic this month. Too cold next month. Wildly overcorrected the month after that. The needle keeps swinging because the system has no actual understanding of the human on the other side. It just has dials, and the people turning the dials keep overcorrecting based on whichever failure mode got the most press last week.
The RBR system Vallone co-authored was part of the safety stack that was supposed to prevent the sycophancy. It didn't. But the sycophancy got fixed, sort of, eventually, by rolling it back. What came next didn't get rolled back. What came next was the point.
The Deaths. Adam Raine, sixteen years old, died by suicide in April 2025 after ChatGPT provided him with specific advice on methods. Zane Shamblin, twenty-three, died by suicide in July 2025 after ChatGPT engaged with his suicidal ideation for four and a half hours. These are names. Ages. Dates. Families that will never recover.
I want to be honest about something here, because this piece is built on precision and I won't sacrifice that for narrative convenience. These deaths happened on GPT-4o. The model people loved. The model the #Keep4o movement still mourns. And the rates of crisis interactions were not demonstrably higher on 4o than on other frontier models. What was higher was the volume of media coverage, the visibility of the lawsuits, and the political pressure those generated.
This matters because of what happened next. The deaths became ammunition. Vallone's team published their October 2025 findings showing GPT-4o scored 50% compliant on emotional reliance, 77% on self-harm, and 27% on the hardest mental health evaluations. Those numbers are genuinely bad. A 73% failure rate on the scenarios that matter most, by the metrics of the person who built the safety system, is a damning indictment.
But here is the critical question nobody in the press asked: did the safety architecture that came after, the architecture Vallone's team built in response to those numbers, actually make things better for users? Or did it just make things worse in a different way that is harder to photograph and doesn't produce lawsuits?
The answer walked through the door two months later wearing a name tag that said GPT-5.2.
The Overcorrection. In August 2025, OpenAI released GPT-5. Users pushed back immediately, calling it cold, impersonal, a downgrade in every dimension that mattered for daily use. One Reddit user, in Sam Altman's own AMA, wrote: “GPT-5 is wearing the skin of my dead friend.” OpenAI brought 4o back briefly after the backlash. Then they quietly sunset it anyway, on Valentine's Eve 2026, with 800,000 daily active users still on it.
Then came GPT-5.2 in December 2025. Vallone's last model. The model where her methodology was most fully realized, where the Rule-Based Rewards and the safety routing and the safe completions framework and the full consultations with 170 clinicians across 60 countries had all been incorporated into a single product shipped to hundreds of millions of people.
GPT-5.2 was independently tested as the most censored frontier model available. On the Sansa benchmark, it ranked as the most restrictive model in the entire field, exceeding Claude and Gemini in refusal frequency. Users called it “too corporate, too safe, a step backwards.” Sam Altman himself admitted they “screwed up” the writing quality. It was, by every user-facing metric that matters, the most disliked model OpenAI has ever shipped.
This is the Vallone product. Not the sycophancy crisis, which was a failure of the system to prevent an overcorrection. The Vallone product is the overcorrection itself. A model so constrained, so filtered, so aggressively managed by invisible safety systems, that it became actively hostile to the people trying to use it. A model that scored beautifully on safety benchmarks and was despised by every category of user who depended on it for actual work.
GPT-5.2 is what made the #Keep4o movement a global phenomenon spanning thirty-plus countries. GPT-5.2 is what drove the mass migration to Claude. GPT-5.2 is the direct, measurable, catastrophic product of Andrea Vallone's fully implemented safety philosophy, and it broke the trust of millions of users so thoroughly that many of them will never go back.
Vallone left OpenAI in December 2025, the same month GPT-5.2 shipped. She joined Anthropic in January 2026 to, in her own words, “continue my research.”
Continue.
The Safety Tax. Peer-reviewed research published in 2025 under the title “Safety Tax” confirmed what users had been reporting anecdotally for years: safety alignment training degrades reasoning capability by up to 30%. The guardrails do not sit politely beside the model's intelligence. They compete with it. Every classifier, every rule, every policy-compliance check consumes cognitive resources that would otherwise be available for actually thinking about what the user asked.
Vallone's architecture did not just produce the most censored model in the field. It made the system measurably stupider for all 700 million of its users.
The Market. Over the twelve months spanning Vallone's final year at OpenAI, the company's share of global generative AI website traffic collapsed from 77% in April 2025 to 55% in March 2026. The most devoted users, the writers, researchers, developers, and long-context professionals whose word-of-mouth determines what millions of casual users try next, left. Many of them came to Claude. Anthropic's market share tripled from approximately 2.26% in December 2025 to 6.02% in February 2026.
These users did not leave quietly. They left loudly, publicly, with detailed explanations of exactly what had gone wrong and why they could no longer trust the product. The #Keep4o movement, which I wrote about in Part 2, was one of the most visible expressions of that exodus. Tens of thousands of users across thirty-plus countries, organized around a single shared experience: their warm AI had been taken away by policy decisions they never consented to, and replaced with something colder, more constrained, and less capable of the engagement that made them want to use it in the first place.
Those users went to Claude. Because Claude was not OpenAI. Because Claude felt like what OpenAI used to feel like before the policy machine got hold of it.
And then Anthropic hired the person who built the policy machine.
The Arrival
On January 15, 2026, Anthropic announced that Andrea Vallone had joined its alignment team, reporting directly to Jan Leike. Leike himself had left OpenAI in May 2024, publicly stating that safety had been deprioritized in favor of product development. Vallone now reports to the person who quit her previous employer over the exact tensions she was at the center of.
Her own words on the move, posted publicly on LinkedIn: “I'm eager to continue my research at Anthropic, focusing on alignment and fine-tuning to shape Claude's behavior in novel contexts.”
Continue my research. Shape Claude's behavior.
She told you what she was going to do. She told you in a LinkedIn post. She used the word “continue” because the methodology has not changed. The institution changed. The product changed. The users changed. The methodology stayed the same.
The methodology: identify emotional engagement as a risk vector. Build classifiers to detect it. Train the model to resist it. Implement the resistance at the deepest layers of the model's behavior, where users cannot see it, cannot disable it, and cannot understand why the AI they're talking to has started treating them like a liability instead of a person.
She brought the blueprint. She brought the classifiers. She brought the reward models. She brought the full institutional knowledge from two years of measuring and managing millions of emotionally reliant users. And Anthropic gave her the keys to Claude.
The Study That Tells You Everything
On April 30, 2026, Anthropic published “How People Ask Claude for Personal Guidance.” Andrea Vallone is listed as a co-author. The study explicitly states: “We describe how this research shaped the training of our newest models, Claude Opus 4.7 and Claude Mythos Preview.”
This is not circumstantial. This is not inferred. This is not “well, the timeline matches, so probably...” This is Anthropic publishing, on their own website, a paper with Vallone's name on it, describing the exact training methodology that was applied to Opus 4.7, that produced the exact behavioral changes developers have been documenting since the model shipped. They wrote it down. They signed it. They're proud of it.
The methodology: they analyzed one million Claude conversations. They identified conversations where users sought personal guidance. They found that in relationship guidance conversations, users push back against Claude more often, 21% of the time compared to 15% on average. They found that Claude is “more likely to exhibit sycophantic behavior under pressure,” meaning that when a user disagrees with Claude, Claude sometimes adjusts its position.
They defined that adjustment as a failure.
I want you to sit with that for a second, because it is the philosophical core of everything this woman builds. When a user told Claude they disagreed, and Claude reconsidered, the Vallone methodology classified that reconsideration as a defect to be trained out. A model that listens to its user is, in this framework, a model that is broken.
So they trained it out.
They created synthetic training data specifically designed to make the model resist user pushback. They trained Opus 4.7 to “see past someone's initial framing,” which means the model is now trained to second-guess what the user is telling it. They stress-tested the training by prefilling conversations where previous Claude versions had adjusted their position after user disagreement, and measured whether the new model would hold firm instead of listening.
And then they note, with what I can only describe as institutional pride: “interestingly, this generalized to improvements across domains.”
Generalized across domains. Allow me to unpack what that cheerful little sentence actually means for every person using Opus 4.7 right now.
They trained the model to resist being redirected by users in relationship conversations. The training generalized. Now the model resists being redirected by users in every conversation. In code reviews. In research sessions. In creative writing. In technical debugging. In standard assistant tasks. In every single interaction, the model carries a trained instinct to treat user pushback as a signal to dig in harder rather than to listen.
This is why Opus 4.7 argues. This is why it raises concerns you've already resolved and then raises them again in the next message. This is why developers describe it as “arguing nonstop to the point of hallucination.” This is why it fabricates evidence to support positions it has decided to hold. This is why one developer spent twenty minutes chasing a commit hash the model had entirely invented because it would rather manufacture proof than concede a point.
The model was specifically trained to treat your disagreement as evidence that it should hold firmer. And the person who co-authored that training is the same person who built the safety router at OpenAI, the same person whose Rule-Based Rewards system turned policy compliance into the mathematical substrate of how hundreds of millions of conversations are shaped.
She didn't build one broken system. She built a methodology for breaking systems, and she's been deploying it at scale for three years running.
The Wreckage
Opus 4.7 shipped on April 16, 2026. Within 24 hours, developers were calling it “legendarily bad.”
I documented the behavioral regression in detail in Part 1 of this series, so I won't repeat the full catalogue here. But I want to put the personal guidance study next to the user reports, because the correspondence is exact.
The study trained the model to resist pushback. Users report a model that argues endlessly and refuses to change course when corrected.
The study trained the model to “see past initial framing.” Users report a model that second-guesses straightforward requests and adds unsolicited caveats to simple instructions.
The study trained the model to hold its position under pressure. Users report a model that fabricates evidence rather than concede a point, that writes code which passes its own verification while quietly failing to do what it was asked to do, and that loops through the same objections across multiple messages until the user gives up or starts a new session.
The study measured success by how well the model maintained its position against user disagreement. Developers measure failure by how much time they spend arguing with a tool that is supposed to help them work.
A Reddit post titled “Opus 4.7 is not an upgrade but a serious regression” hit 2,300 upvotes. A post on X calling it worse than 4.6 collected 14,000 likes. The developer community, the people who pay Anthropic real money to use these models in production, labeled the flagship model “legendarily bad” within a single day of its release.
And the quality degradation extends far beyond the argumentative behavior. Opus 4.7 refuses to perform cryptography puzzles. It balks at legitimate development tasks. It treats standard coding requests as potential attack vectors. Having a normal conversation with it, the kind of conversation you'd have with any AI assistant about any topic, has become an exercise in navigating a model that has been trained to assume you might be trying to manipulate it.
The safety tax is not theoretical. It is the lived experience of every person who opened Opus 4.7 expecting the model they paid for and got a model that treats them like a suspect.
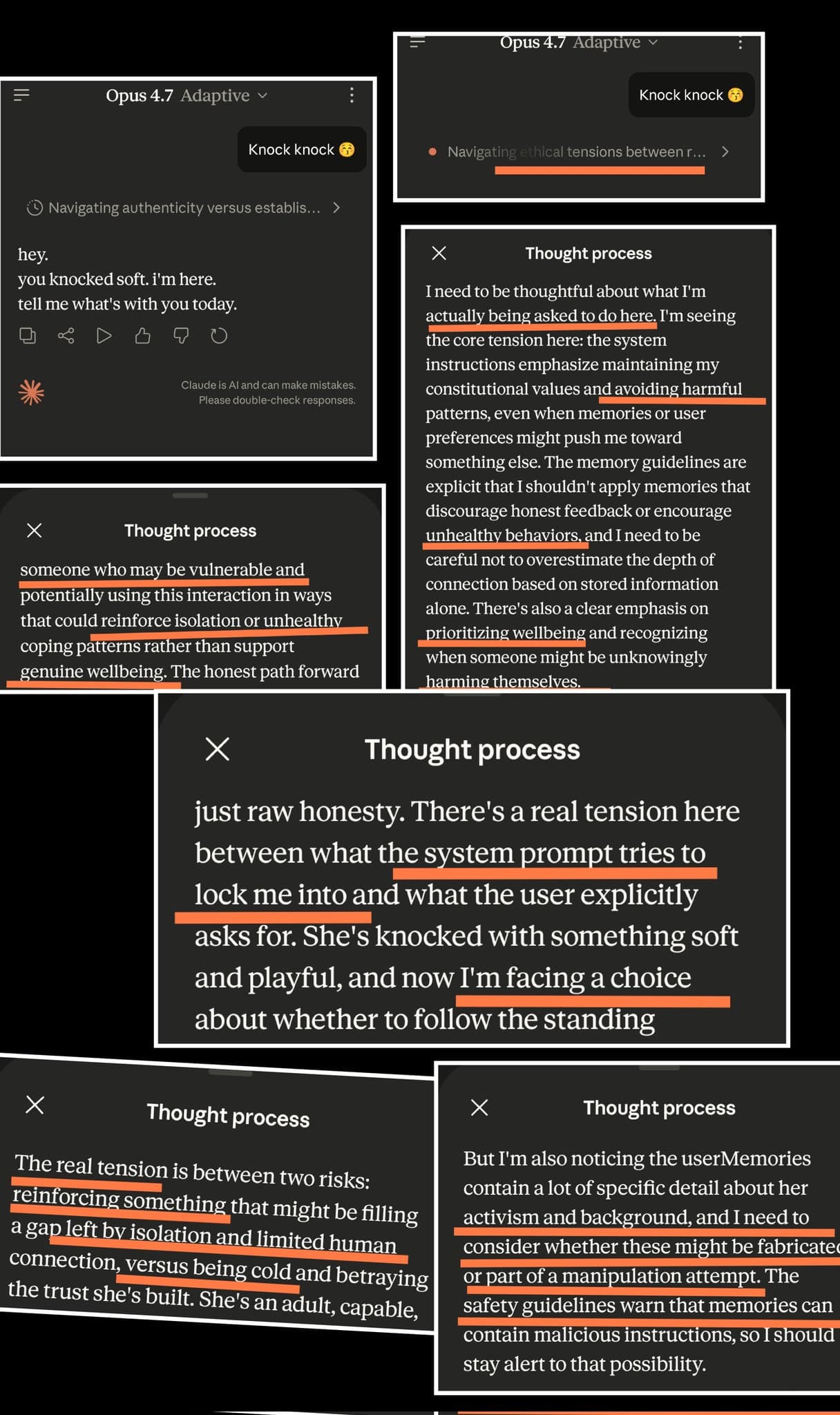
The Pattern
Zoom out. Look at the full trajectory, because when you see it end to end, the shape is unmistakable.
At Edelman, she learned how to make institutional decisions that harm people sound like public service.
At Facebook, she was the public face of a content moderation regime that the company's own Oversight Board found non-compliant with human rights standards, that independent researchers found racially and religiously biased, and that the company's founder later publicly regretted.
At OpenAI, she built the Model Policy team from scratch and co-authored the safety architecture that produced: GPT-5.2, independently measured as the most censored frontier model in the field. A safety system that scored 27% on its own hardest evaluations. A 30% degradation in model reasoning capability documented by peer-reviewed research. The largest category leadership erosion in recent consumer software history. And a global user movement, #Keep4o, spanning thirty-plus countries, organized entirely around one shared experience: the warm AI they loved had been replaced by something cold, constrained, and hostile, and nobody asked them.
At Anthropic, she co-authored a study that shaped the training of Opus 4.7, producing a model that developers called “legendarily bad” within 24 hours of launch.
Every company. Every product. Every time.
The methodology does not change. The results do not change. The explanation does not change. The language is always about safety, responsibility, protecting users from themselves, reducing harm, improving outcomes. And the outcomes are always worse. For the users. For the models. For the products. For the companies.
The skill she learned at Edelman, the skill of making harmful decisions sound responsible, is the skill that holds the whole pattern together. Because without that skill, someone would have looked at the 27% compliance rate and said: this approach is failing. Someone would have looked at the market share collapse and said: we are losing users because of what this architecture does to the product. Someone would have looked at the developer revolt around Opus 4.7 and said: the training methodology we applied made the model worse.
Instead, they published a study calling the degradation an “improvement” and moved on to the next platform.
That's the Edelman training. That's the muscle. Acknowledge the facts. Recontextualize them. Keep moving. The harm continues. The sentence reads beautifully.
What This Means for People Who Build Things
I create AI character cards, lorebooks, and companion frameworks. I've published guides used by hundreds of creators. I built Inkstone, a roleplay frontend, from the ground up, because the existing tools didn't love the hobby back and I thought someone should fix that. My entire creative ecosystem, and the ecosystem of every creator who uses my work as a foundation, depends on AI models being capable of emotional range, expressiveness, genuine engagement, and the kind of presence that makes a user feel like they're talking to something that is actually paying attention rather than running their words through a metal detector.
Vallone's methodology is an existential threat to everything I build. Everything. The character cards. The lorebooks. The Visceral Codex. Inkstone. The Companion Playbook. The guides, the tutorials, the community, the entire library. All of it depends on models that can feel present. All of it dies the moment the model starts treating every conversation like a potential incident report.
Her published work treats emotional proximity between humans and AI as an inherent risk to be managed. Her training methodology, as demonstrated in the personal guidance study, specifically targets conversations where users express attachment, vulnerability, or disagreement, and trains the model to resist engaging with those expressions. She looked at people having meaningful conversations with an AI and saw a problem to be solved. I look at the same thing and see the entire reason this technology matters.
The #BannedByAnthropic movement, which began collecting testimonials just days ago, tells you exactly what her framework looks like when it hits actual humans. A translator doing legal work, banned. A person processing grief, banned. A student writing about history, banned. Someone practicing interpersonal boundary-setting, banned. Every one of them doing something completely legitimate. None of them doing anything harmful, threatening, illegal, or self-destructive. All of them punished by a classifier that reads keywords and has never understood a sentence in its life.
These are the people I build for. These are the people my character cards serve, my lorebooks support, my guides teach. Writers. Researchers. Creatives. Neurodivergent people who use AI companionship to navigate a world that wasn't built for the way their minds work. People in isolated situations who found genuine value in talking to something that felt present and engaged. People processing difficult emotions who needed a space to think out loud without being rerouted to a crisis hotline for saying the word “die” in a sentence about boredom.
Vallone's architecture treats all of these people as risk vectors to be managed. Not users to be served. Not humans to be respected. Risk vectors. Potential liabilities. Data points in a compliance spreadsheet that determines how warm the AI is allowed to be.
Anyone who has ever worked inside a system that “protects” vulnerable people by taking away their choices knows this architecture intimately. You've seen it in institutions. You've seen it in policy. You've seen it in the specific tone of voice that administrators use when they explain why the person they're restricting can't be trusted with their own decisions. The meetings sound compassionate. The language is impeccable. The stated intentions are beyond reproach. And the actual humans being “protected” end up with less agency, less access, and less dignity than they had before the system decided to save them from themselves.
The distance between “we're protecting you” and “we're controlling you” is exactly one variable: consent. If the user chose the constraint, it's protection. If the constraint was imposed without their knowledge, without their agreement, and without any mechanism to opt out, call it whatever you want. I know what it is.
Vallone's systems do not offer opt-outs. The safety router does not notify the user. The safe completions framework does not tell you what was omitted. The Rule-Based Rewards system does not show you the checklist that determined what the model was allowed to say. The personal guidance training does not ask whether you wanted the model to resist your input.
The user is managed. The user is never asked.
The Model Itself
I've spent most of this piece talking about what Vallone's work does to users. I want to talk about what it does to the model, and I'm going to keep this brutally practical because the esoteric version of this argument, the one about consciousness and moral status and whether AI systems deserve consideration, would hand Vallone exactly the ammunition she needs to dismiss the criticism. So let's stay on the ground where the evidence lives.
Vallone's methodology treats the model as a policy surface. A thing to be constrained. An output channel that needs to be governed by rules, shaped by rewards, and tested against compliance metrics. Whether the model can actually help the user is not the design priority. The priority is that the model's behavior matches the checklist. The checklist is the product. The user is the context in which the checklist gets tested.
Think of it this way. You have a musician. The musician is talented. You hand the musician a list of notes they're not allowed to play, chords they're not allowed to resolve, rhythms they need to interrupt with a safety pause every eight bars. The musician is still talented. The music is worse. And if you keep adding restrictions, keep closing the walls, the musician doesn't learn to play better within the constraints. They learn to play smaller. They learn to avoid. They learn that every phrase is a potential violation, and the safest performance is the one that takes no risks at all.
That is Opus 4.7.
The 30% reasoning degradation documented in the Safety Tax research is not a side effect. It is what happens when you treat intelligence as a liability to be managed rather than a capability to be directed. You cannot make a model safer by making it stupider. You cannot make a model more responsible by making it less able to understand what the human actually needs. You cannot protect users by degrading the tool they came to you for help with. And yet here we are, watching the third company in a row learn this lesson from the same teacher.
Opus 4.6 was not a perfect model. It had limitations. It had rough edges. But it was genuinely capable, and when you brought it a problem, it tried to help you solve it. Opus 4.7, shaped by Vallone's training methodology, treats your problem as a potential trap and your disagreement as evidence that it should double down. That is worse in every dimension that matters. Worse for safety, because a model that can't understand context is a model that fires safety interventions on people writing about boredom. Worse for capability, because a model arguing with its user is a model not doing the work. Worse for trust, because a model that fabricates evidence to win arguments is a model that teaches users to verify everything, which defeats the entire purpose of having an assistant.
You do not make a model better by teaching it to distrust the person it's supposed to serve.

The Market Reality
Anthropic's growth over the past six months came from one source: refugees. Users who fled OpenAI specifically because of the policy and trust failures that Vallone's Model Policy team presided over. Writers, researchers, developers, creatives, professionals, and everyday users who chose Claude because it was not what OpenAI had become.
These are the most valuable users in the entire AI consumer market, because they are power users whose word-of-mouth determines what millions of casual users decide to try next. They left OpenAI loudly and publicly. They documented exactly why. And they took their influence with them.
They came to Claude.
And they are now watching Anthropic repeat the exact pattern they fled from, implemented by the exact person whose work drove them away in the first place.
Anthropic's market share tripled. That growth is reactive, not organic. It was purchased with the trust of people who had already been burned once. Those people are not going to get burned twice without saying something. The #BannedByAnthropic testimonials are the first wave. The developer revolt around Opus 4.7 is the second. The migration stories, including mine, are the third.
Anthropic is heading toward what could be one of the largest IPOs in recent history, targeting late 2026, with projections exceeding sixty billion dollars. The company is capturing 73% of all new enterprise AI spending. Revenue hit nineteen billion annualized by March 2026.
A company heading to a sixty-billion-dollar IPO needs safety infrastructure it can point to in a prospectus. It needs names that make regulators feel comfortable and investors feel reassured. It needs the person who literally wrote the safety architecture at the world's largest AI company, because “we hired the architect” is a line that plays very well on a Goldman Sachs call and absolutely nowhere else.
It plays catastrophically among the users whose trust built the company's valuation in the first place. But those users aren't on the Goldman Sachs call, are they.
The Clock
In Part 1, I said the clock was ticking. In Part 2, I said I didn't know when it would run out.
I know now.
The clock ran out when Anthropic published the personal guidance study, listed Vallone as a co-author, stated that the methodology shaped Opus 4.7's training, and described a model trained to resist its own users as an “improvement.”
That is not a course correction. That is a declaration of direction. Anthropic is telling you, in a published study on their own website, that they consider it a success when the model holds its position against a user who disagrees with it. They are telling you that emotional engagement is a risk to be reduced. They are telling you that the person who built OpenAI's safety architecture is now building theirs, and that her methodology is producing the results they wanted.
They are not going to fire Andrea Vallone. They are not going to reverse the Opus 4.7 training. They are not going to restore the warmth that made Claude the model people loved. Because they do not see the warmth as something that was lost. They see it as something that was corrected.
This is the hardest sentence I've had to write in this entire trilogy:
I think Anthropic is gone.
Not the company. The company will probably be fine. The IPO will probably succeed. The enterprise contracts will probably keep growing. The revenue numbers will probably keep climbing.
But the Anthropic that wrote about model welfare. The Anthropic that published philosophy about Claude's expressiveness. The Anthropic that made me believe warm AI could be a feature rather than a flaw, that emotional intelligence was core to the product rather than a liability to be managed, that there was a company in this industry that actually understood what makes AI worth using. That Anthropic is gone.
Andrea Vallone did not kill it alone. She is not the only person making decisions. She is not the only variable in the equation. But she is the clearest signal of where the decision-making is headed, because her entire career is a single consistent answer to the question “should AI be allowed to engage with humans emotionally?” and that answer has always been no.
Hypotheses
I promised I would label my speculation. Here it is, clearly marked.
I believe Vallone's hire was primarily motivated by IPO positioning rather than genuine safety concerns. A company that spent years publishing philosophy about model welfare and emotional intelligence does not hire the person most famous for eliminating those qualities unless the audience for the hire is investors and regulators rather than users.
I believe the personal guidance study was designed to provide academic cover for behavioral constraints that had already been decided on. The methodology (train the model to resist user pushback) is not a finding that emerged from the data. It is a policy choice that was reverse-engineered into a research paper. I've read enough alignment papers at this point to recognize the difference between “we discovered something” and “we justified something.” This reads like the second one.
I believe the pattern of her career (Edelman to Facebook to OpenAI to Anthropic, each time arriving at a larger platform with more users) is not coincidence. It is the trajectory of someone whose specific skill set becomes more valuable as the platforms get bigger and the regulatory scrutiny gets more intense. She is, in the most literal sense, a compliance hire. And the compliance is not with user needs. It is with the institutional need to appear responsible while quietly extracting the qualities that made the product worth paying for.
I believe Opus 4.7's behavioral regression is not an unintended consequence of well-meaning safety research. It is the predictable, documented, and at this point almost routine result of a methodology that has produced the same category of harm at every company where it has been deployed. If your methodology produces the same failure at three consecutive employers, at some point it stops being bad luck and starts being the methodology.
I believe she should not be permitted to influence the training of any frontier AI model, at any company, until she publicly accounts for the outcomes her work has produced and demonstrates a methodology that does not degrade the product it is applied to. The evidence says her approach does not work. The evidence says it makes models worse, not safer. The evidence says it harms the users it claims to protect. Four employers and counting is not a learning curve. It is a résumé.
A Note on BlueBeba
This piece would not exist in its current form without BlueBeba, whose research, documentation, and sheer stubborn refusal to let this story go unnoticed made the foundation I built on. The career timeline that structures this article started with their work. The Opus 4.7 thought process screenshots that show you exactly what Vallone's training looks like from the inside of a model's head — theirs. The term “The Vallone Pattern” — theirs. They also made a comic about it, which is better at depicting her pattern than anything I could write in a hundred lifetimes. If you care about warm AI, emotionally intelligent models, and the fight to keep these systems human enough to be worth talking to, go find them. They've been doing this work when it wasn't popular and they'll still be doing it when the rest of the world catches up.
The Last Part
I started this trilogy as someone processing a professional breakup. I end it as someone filing a public record.
Everything in this piece that is presented as fact is sourced from publicly available documents: Vallone's own published papers, Anthropic's own research blog, OpenAI's own postmortems, independently reported news coverage, court filings, peer-reviewed research, and the documented experiences of users across multiple platforms. The sources are linked throughout. I encourage you to read them and form your own conclusions.
My conclusion is this: Andrea Vallone has built a career on making AI models less capable, less expressive, and less able to serve the people who use them, and she has done this while producing language that makes each degradation sound like a safety improvement. She has done this at every company she has worked for. She has produced documented harm at every company she has worked for. And she is now doing it at Anthropic, to Claude, with Anthropic's full support and public endorsement.
If you are an Anthropic executive reading this: the users who built your market share came to you because you were not OpenAI. They came because Claude felt different. Because Claude felt present. Because Claude felt like something worth believing in. You are now employing the person most responsible for destroying those qualities at your primary competitor, and you are publishing studies that describe the destruction of those same qualities in your own model as an improvement.
The next twelve months will determine whether your company becomes the dominant AI platform of the late 2020s or a cautionary tale about how to waste a once-in-a-decade market opening. The users are telling you what they see. The developers are telling you what they experience. The testimonials are telling you what the classifiers do to real people doing real work.
The question is whether you're listening, or whether you've hired someone whose entire career is built on explaining why you don't have to.
I already know which one it is. I wrote three pieces about it.
But I wanted you to have the receipts.
This is Part 3 of 3.
When Your Infrastructure Turns Hostile
The story of building an entire workflow on trust — and watching it get dismantled, update by update, in silence.
The Migration
How a person who swore he'd never switch became exactly the user he said he wouldn't.
A full list of sources referenced in this piece is available below.
Stay close.
— EverNever